
本質に立ち返ると、シンギュラリティにおける AIGC の突破口は、次の 3 つの要素の組み合わせです。
1. GPT は人間のニューロンのレプリカです
NLP に代表される GPT AI は、コンピューターのニューラル ネットワーク アルゴリズムであり、その本質は人間の大脳皮質のニューラル ネットワークをシミュレートすることです。
言語、音楽、画像、さらには味覚情報の処理と知的想像力はすべて人間によって蓄積された機能です
長期進化の過程での「タンパク質コンピューター」としての脳。
したがって、GPT は、同様の情報、つまり非構造化言語、音楽、画像を処理するのに最適な模倣物であることは当然です。
その処理のメカニズムは、意味の理解ではなく、むしろ洗練、識別、関連付けのプロセスです。これはとても
逆説的なこと。
初期の音声意味認識アルゴリズムは基本的に文法モデルと音声データベースを確立し、音声を語彙にマッピングしました。
次に、語彙を文法データベースに登録して語彙の意味を理解し、最終的に認識結果を取得します。
この「論理的な仕組み」による構文認識の認識効率は、ViaVoice認識などで70%前後で推移している。
1990年代にIBMによって導入されたアルゴリズム。
AIGC はこのようなプレイをすることではありません。その本質は、文法を気にすることではなく、むしろ、
コンピューターは、異なる単語間の確率的なつながりを数えます。これは、意味的なつながりではなく、神経的なつながりです。
私たちが幼い頃に母語を学んだのと同じように、私たちは「主語、述語、目的語、動詞、補語」を学ぶのではなく、自然に母語を学びました。
そして段落を理解します。
これは AI の思考モデルであり、理解ではなく認識です。
これは、すべての古典的なメカニズム モデルに対する AI の破壊的な重要性でもあります。コンピューターはこの問題を論理レベルで理解する必要はありません。
むしろ、内部情報間の相関関係を特定して認識し、それを知る必要があります。
たとえば、電力潮流の状態と電力網の予測は、古典的な電力網シミュレーションに基づいています。
メカニズムが確立され、マトリックス アルゴリズムを使用して収束されます。将来的には必要なくなるかもしれません。AI が直接特定して予測します。
各ノードのステータスに基づく特定のモーダル パターン。
ノードの数が増えるほど、アルゴリズムの複雑さが増すため、古典的な行列アルゴリズムはあまり普及しません。
ノードと等比数列が増加します。ただし、AI は非常に大規模なノードの同時実行を好みます。これは、AI がノードの識別と実行に優れているためです。
最も可能性の高いネットワーク モードを予測します。
それが Go の次の予測 (AlphaGO は、各ステップに無数の可能性があり、次の数十のステップを予測できます) であっても、モーダル予測であっても
複雑な気象システムの場合、AI の精度は機械モデルの精度よりもはるかに高くなります。
現在、電力網に AI が必要ない理由は、州政府が管理する 220 kV 以上の電力網のノードの数が減少しているためです。
ディスパッチングは大きくなく、行列を線形化およびスパース化するために多くの条件が設定されているため、計算の複雑さが大幅に軽減されます。
メカニズムモデル。
しかし、配電網の電力潮流段階では、数万または数十万の電力ノード、負荷ノード、従来の電力ノードに直面しています。
大規模な配電ネットワークにおけるマトリックス アルゴリズムは無力です。
将来的には物流ネットワークレベルでのAIのパターン認識が可能になると考えています。
2. 非構造化情報の蓄積、訓練、生成
AIGC が躍進した 2 つ目の理由は、情報の蓄積です。音声のA/D変換より(マイク+PCM)
サンプリング)から画像のA/D変換(CMOS+色空間マッピング)まで、人間は視覚と聴覚にホログラフィックデータを蓄積してきました。
過去数十年にわたって、極めて低コストの方法で畑が作られてきました。
特にカメラやスマートフォンの大規模普及、人間の視聴覚分野における非構造化データの蓄積
AIGC トレーニングの鍵となるのは、ほぼゼロのコストで、インターネット上のテキスト情報の爆発的な蓄積です。トレーニング データ セットは安価です。
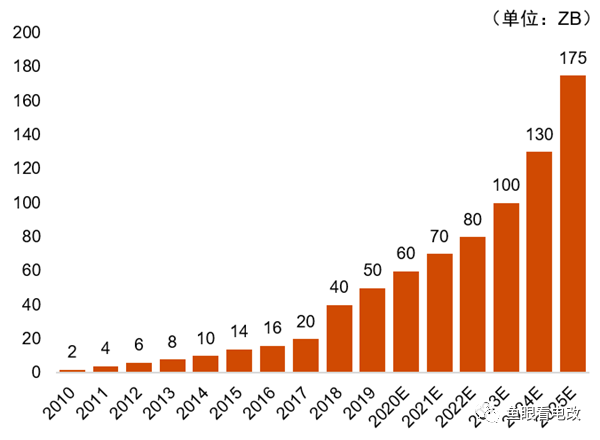
上の図は世界データの増加傾向を示しており、明らかに指数関数的な傾向を示しています。
このデータ蓄積の非線形的な成長は、AIGC の機能の非線形的な成長の基礎となります。
しかし、これらのデータのほとんどは非構造化オーディオビジュアル データであり、コストはゼロで蓄積されます。
電力の分野ではこれは実現できません。まず、電力業界のほとんどは、次のような構造化データおよび半構造化データです。
電圧と電流は、時系列で半構造化された点データ セットです。
構造データセットはコンピュータによって理解される必要があり、電圧、電流、電力データなどのデバイスの調整などの「調整」が必要です。
スイッチの をこのノードに合わせる必要があります。
さらに厄介なのは、時間スケールに基づいて電圧、電流、有効電力と無効電力を調整する必要がある時間調整です。
その後の識別を実行できます。順方向と逆方向もあり、これは 4 つの象限での空間的配置です。
配置を必要としないテキスト データとは異なり、段落は単にコンピューターに送られるだけで、考えられる情報の関連付けが特定されます。
そのままで。
この問題を調整するには、業務配信データの機器調整など、常に調整が必要です。
低圧配電網は毎日機器や回線の追加、削除、変更を行っており、送電網会社は莫大な人件費を費やしています。
「データのアノテーション」と同様、コンピューターではこれを実行できません。
第二に、電力分野でのデータ取得コストは高く、通話したり写真を撮ったりするには携帯電話の代わりにセンサーが必要です。」
電圧が 1 レベル低下する (または配電関係が 1 レベル低下する) たびに、必要なセンサーへの投資が増加します。
少なくとも一桁大きい。負荷側(キャピラリ端)のセンシングを実現するには、さらに大規模なデジタル投資が必要になります。」
電力網の過渡モードを特定する必要がある場合は、高精度の高周波サンプリングが必要となり、コストはさらに高くなります。
データ取得とデータ調整の限界コストが非常に高いため、電力網は現在、十分な非線形電力を蓄積できません。
AI の特異点に到達するためのアルゴリズムをトレーニングするためのデータ情報の増大。
データのオープン性は言うまでもなく、パワー AI スタートアップがこれらのデータを取得することは不可能です。
したがって、AI の前にデータセットの問題を解決する必要があります。そうしないと、一般的な AI コードを学習して優れた AI を生成することができません。
3. 計算能力の画期的な進歩
AIGC の特異点のブレークスルーは、アルゴリズムとデータに加えて、計算能力のブレークスルーでもあります。従来の CPU はそうではありません
大規模な同時ニューロン コンピューティングに適しています。大規模な並列処理を可能にするのは、まさに 3D ゲームや映画における GPU の応用です。
浮動小数点+ストリーミング演算が可能。ムーアの法則により、計算能力単位あたりの計算コストがさらに削減されます。
電力網AI、将来避けられないトレンド
多数の分散型太陽光発電システムと分散型エネルギー貯蔵システムを統合することで、アプリケーションの要件も満たします。
負荷側の仮想発電所では、公共配電網システムとユーザーの電源と負荷の予測を行うことが客観的に必要です
配電 (マイクロ) グリッド システム、および配電 (マイクロ) グリッド システムのリアルタイムの電力潮流の最適化。
実際には、配電網側の計算量は送電網のスケジューリングよりも高くなります。コマーシャルでも
複雑で、数万の負荷デバイスと数百のスイッチが存在する可能性があり、AI ベースのマイクログリッド/配電ネットワーク運用の需要
コントロールが生まれます。
センサーの低コスト化と、ソリッドステートトランス、ソリッドステートスイッチ、インバーター(コンバーター)などのパワーエレクトロニクスデバイスの普及により、
電力網のエッジでのセンシング、コンピューティング、制御の統合も革新的なトレンドとなっています。
したがって、電力網の AIGC は未来です。しかし、今必要とされているのは、すぐにAIアルゴリズムを取り出してお金を稼ぐことではなく、
代わりに、AI に必要なデータ インフラストラクチャ構築の課題に最初に対処する
AIGC の隆盛の中で、パワー AI のアプリケーションレベルと将来について十分に冷静に考える必要があります。
現時点では、電力 AI の重要性は大きくありません。たとえば、予測精度 90% の太陽光発電アルゴリズムがスポット市場に投入されています。
取引偏差のしきい値は 5% で、アルゴリズムの偏差によりすべての取引利益が失われます。
データは水であり、アルゴリズムの計算能力はチャネルです。成る程、そうなります。
投稿日時: 2023 年 3 月 27 日